EnemyUnknown Battlegrounds A trained surviver in the harsh environment!
Video
Project Summary:
Our agent in this submission is a prototype of our final agent. The agent should survive in the world as long as possible by learning to avoid enemies’ attacks. If attacked, the agent’s health points will be deducted and it will die and quit immediately when its health points reaches 0. Our goal is make our agent survive in a random world longer by integrating q learning algorithm in its learning part.
Approach:
For now we have 3 Zombies and 2 pigs spawn randomly in a 40X40 flat ground. And our basic algorithm idea is from Assignment2. The q learning algorithm’s logic is quite similar to the pseudo code given below.

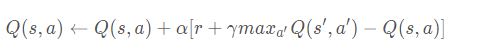
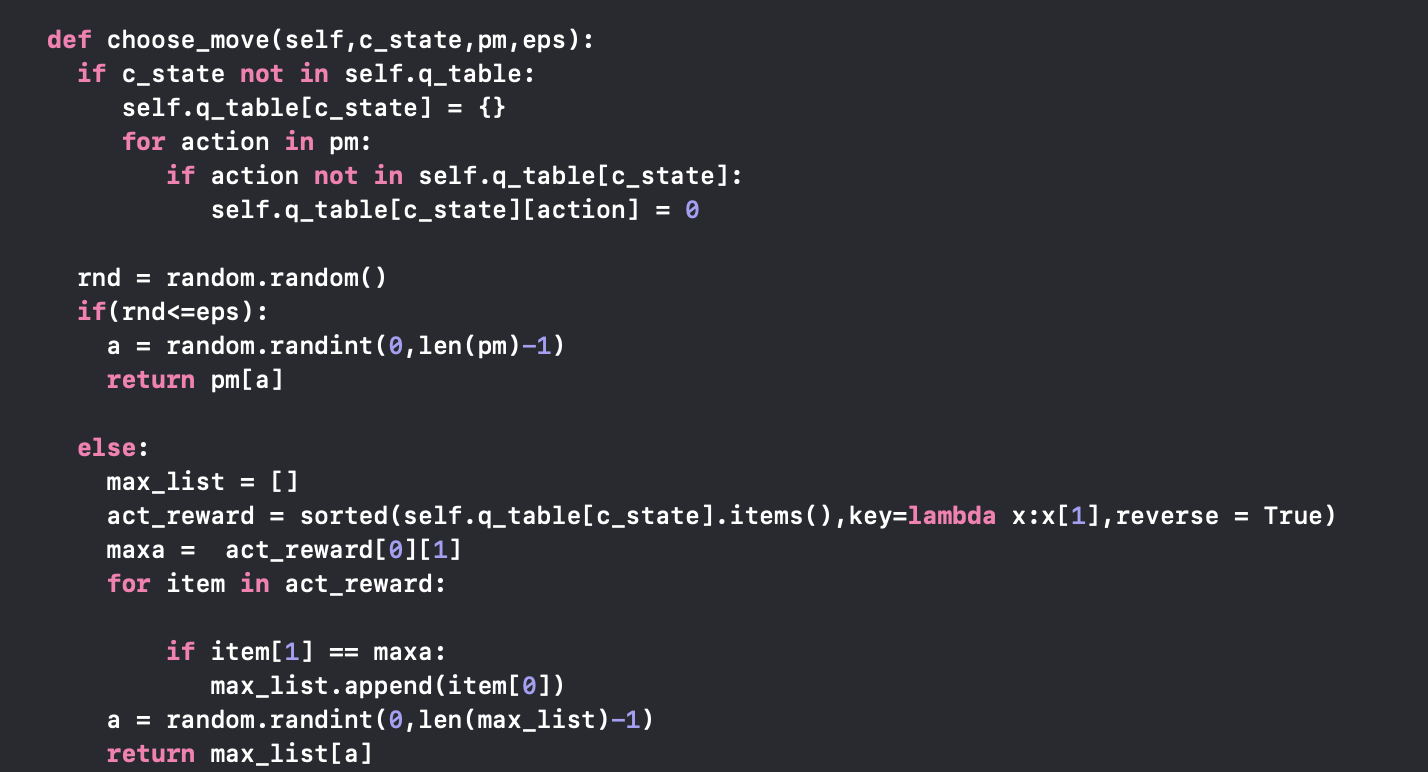
First of all, the agent with its current state will get a list of possible actions and choose a move by implementing ε-Greedy Policy. Instead, The agent returns a random action with probability eps, but with (1-eps) it picks the action with the highest Q-value. The code below perform the above description.
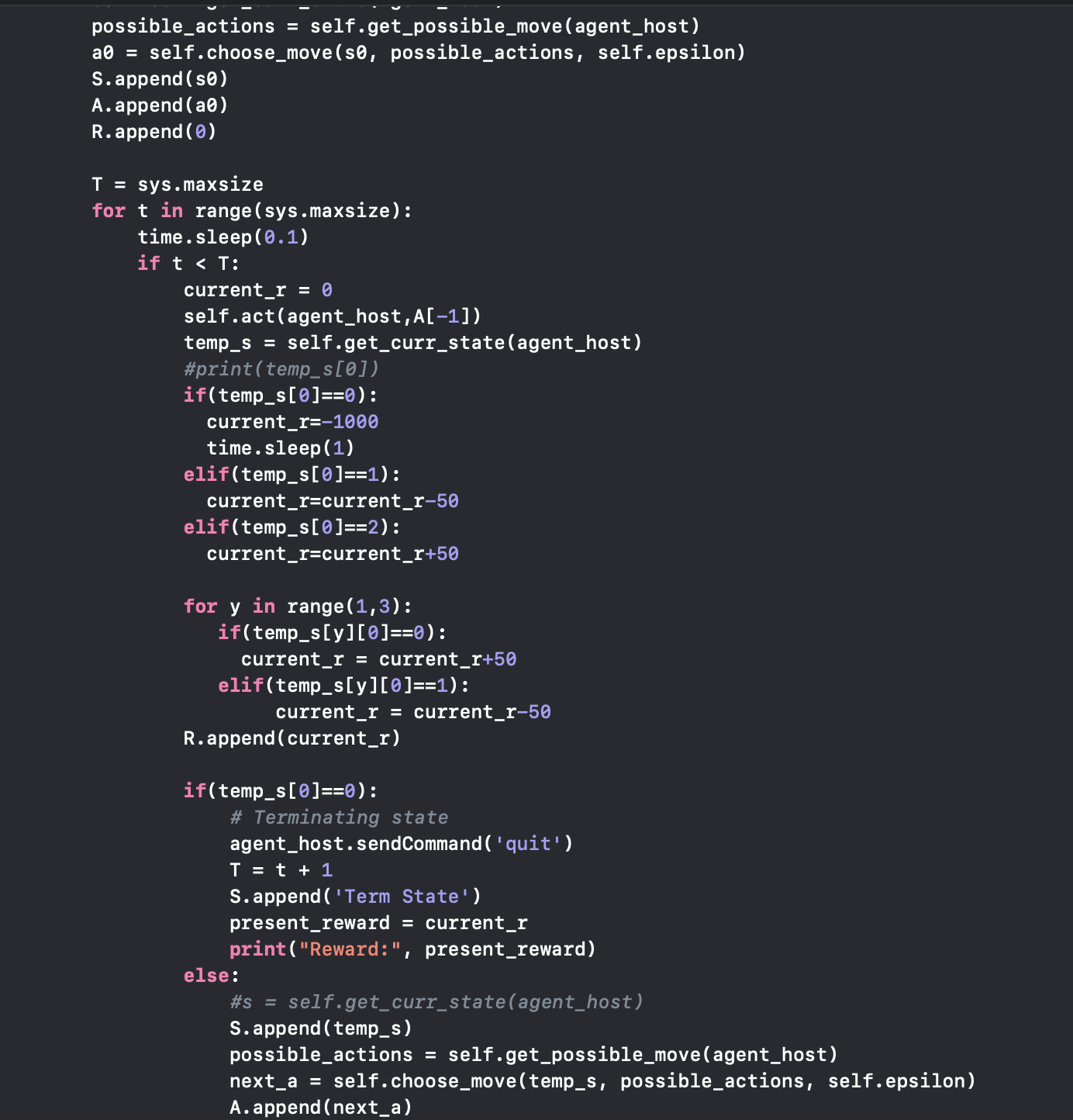
After every move of our agent, the agent will get a current state and store the privous state. There are states we have. The first one is our health points, the second and third one is the relative distance of the closest two enemies surrounding the agent. The health points of 0 means the agent dies and reward is -1000. 1 means half alive and the reward is -50. 2 means full alive and the reward is +50. The distance value of 0 means greater distance between the agent and the enemy and the reward is +50. The distance value of 1 means closer distance and reward is -50. The agent will always compute the total reward it gains by checking its current state and it stores current and next status, action, reward for upating q-table. If agent find its health points reach 0, it will return the final reward to the terminal and quit the game immediately without continuing any afterward steps. If it is still alive, the agent will continue to find the next action and act. The code below perform the above description.

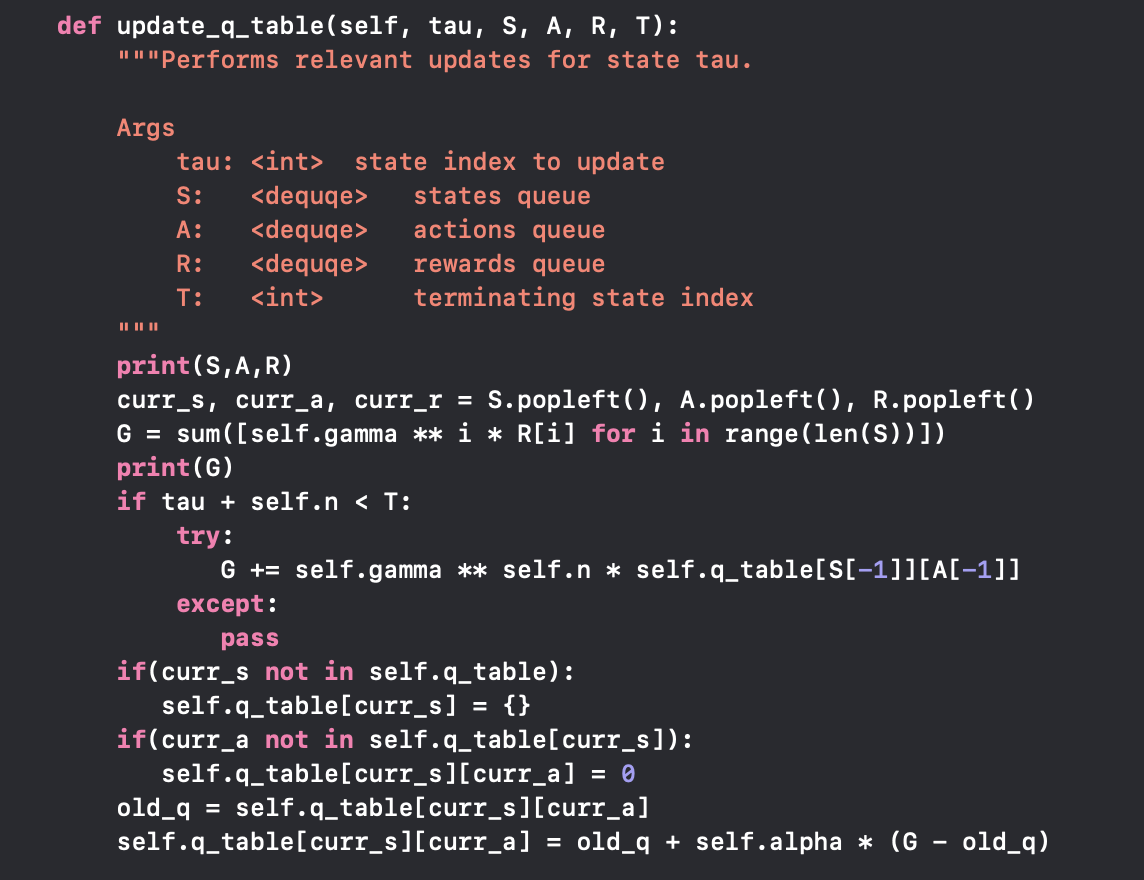
The agent will deal with the current reward after getting into each move. The agent will update the q_table, which we stores the table as one of our agent. The basic logic of the implementation of updating q_table is Bellman equation provided during the lectures. The equation looks like this: Q(s,a) <- Q(s,a)+alpha(r+y(maxQ(s’,a’)-Q(s,a))). According to the tutorial online, the formula means “the expected long-term reward for a given action is equal to the immediate reward from the current action combined with the expected reward from the best future action taken at the following state.” The code below perform the above description.
Evaluation
We just easily use the alive time of the agent to evaluate our agent’s performance. Here is the data after 700 episode(we will show the best move after every 5 episode):
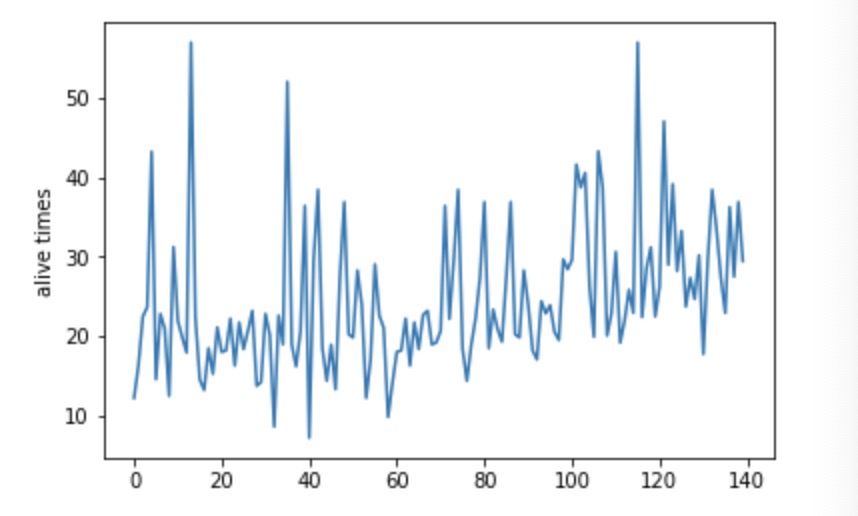
Generally, the alive time of the agent is improved. As we can see from the plot, the alive time for our agent is increasing gradually from first 10s to the last 30s. However, the survial time is still too low than we expected. I think we have too many possible states and rewards which are too complicated for q-learning algorithm to learn. Also, there are some states we don’t expect because the enemies and the traps are born randomly. Thus, dying in the pitfall in a bad luck at the start of trainning will affect the alive time greatly. What’s more, the reason that the alive time is still low is our learning rate is too small(0.03). As a result, we decide to improve our algorithm to learn and find a better reward for each state that will cause the agent to die and increase our learning rate. The algorithm is the most significant part we should do now before the final.
Remaining Goals and Challenges:
Our remaining goal is to make our agent more intelligent. To achieve this goal, our algorithm should be improved still. We plan to add the deep q learning algorithm to the learning part, which would perform better for larger state space and unknown transition probabilities. The most challenging part for our team right now is how to integrate this algorithm correctly in our current code. We need to add a linear function as our value function to q_table. The neural network also could be considered in order to solve more complicated situation.
Our next goal is to add pigs into the world, which can be exploited to increase our health points by eliminating them. It is also challenging to integrate this action and reward to our algorithm. We will evaluate this action later. We might use some similar pseudo code of deep q learning into our later modification.